
Unlocking the Transformer Model
-
date_range 18/11/2023 21:48 infosortdefaultlabelMachine LearningNLPTransformerSelf-Attention
The introduction of the Transformer model initially aimed to address the limitations of convolutional neural networks (CNNs) and recurrent neural networks (RNNs) in machine translation. The goal was to enable parallel computation and effectively handle long-range dependencies in sequences. While attention mechanisms were previously popular in computer vision for tasks like image classification and detection, the Transformer adapted them to enhance the efficiency and scalability of neural networks, especially in sequence-to-sequence tasks such as machine translation.
The Transformer overcomes certain challenges posed by CNNs and RNNs in this context:
- It reduces sequential operations compared to RNNs, improving computational efficiency.
- The model learns bidirectional information simultaneously, distinguishing itself from bidirectional LSTM models that learn directions independently.
- The Transformer excels at capturing long-range dependencies, a critical factor in tasks like machine translation.
Table of Contents
- The Transformer Architecture
- Advantages of the Transformer Model
- Disadvantages of the Transformer Model
- Common Q & A
- Reference
The Transformer Architecture
As shown in the figure below,
The transformer model consists of encoder and decoder parts involving a multi-layer architecture. The input sequences are initially embedded into Query, Key, and Value vectors. These vectors serve as the basis for the self-attention mechanism, enabling simultaneous consideration of various sequence elements. The self-attention mechanism computes attention scores, emphasizing the importance of different elements and capturing intricate dependencies efficiently. With multiple self-attention heads, the model gains the ability to discern complex patterns. The attention-weighted vectors undergo feedforward transformations across multiple layers, refining the model’s understanding of contextual relationships. During training, the model’s parameters are updated through backpropagation and optimization processes, minimizing the difference between predicted and actual outputs. This comprehensive data flow, characterized by parallelizable computations and attention mechanisms, ensures the Transformer effectively learns intricate sequential dependencies, contributing to its success in various natural language processing tasks.
It is noteworthy that the encoder part stacked is the basis of BERT model, and the decoder part stacked is the basis of GPT.
There are four main blocks in the transformer architecture.
Word Embedding
The input is a string of word sequences. It uses a word embedding algorithm to obtain the embeddings of tokens from the word input. For example, one-hot embedding can be employed as the word embedding method.
Positional Embedding
This addresses the issue of word order. It encodes the position as an integer and embeds it as a vector. Positional embedding is added to the input embeddings at the bottoms of the encoder and decoder stacks. While directly concatenating it might impact positional encoding, in practice, it appears to work well.
The paper employs sine and cosine functions with different frequencies:
\[PE(pos, 2i) = sin(pos/10000^{2i/d_model}\] \[PE(pos, 2i+1) = cos(pos/10000^{2i/d_model}\]Attention mechanism
It uses query \(Q\), key \(K\), value \(V\), simulating a query in the database with keys and values. The mechanism compares the similarity of the query to each key and finds the value corresponding to the most similar key. The attention scores are calculated as shown in the figure here:

where
\[sim(Q, K) = Q*K/\sqrt(d_k)\]\(Q\), \(K\), \(V\) dimensions are \(n\) x \(d\), Attention’s dimension is \(n\) x \(d\).
Then the extened attentions of Masked multi-head Attention and Multi-head Attention are used.
Here is the masked Mutlti-head Atttention.
It masks some values for decoding output. The output should not depend on future outputs.
\[Attention(Q, K, V) = softmax(sim(Q, K^T))*V\] \[sim(Q, K) = (Q*K + M)/\sqrt(d_k)\]where
\(M\) is a maksed matrix of \(0\) or \(-\infty\), which to make the exponential of \(-\infty\) as \(0\), also masking before exponential makes the whole distribution prob as \(1\).
Multi-head Attention shown below are calculated in parallel with $h$ attention layers.
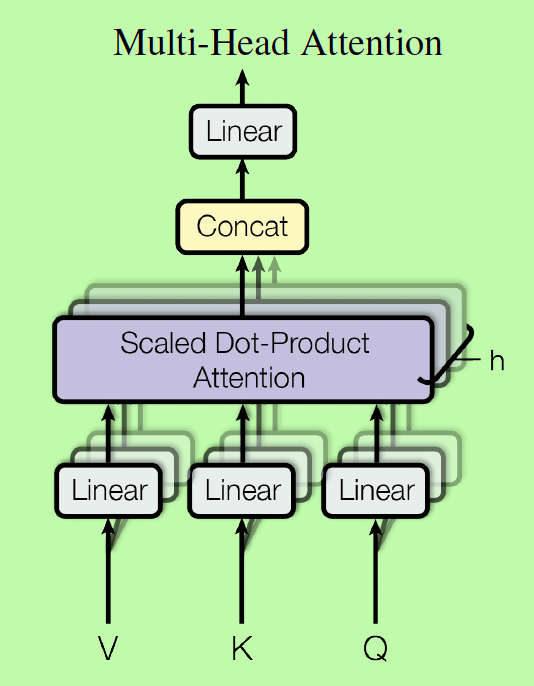
where
\[head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)\]Layer normalization:
Considering of large and long input and output word size, we can normalize the value to keep in a range.
They normalize the values after positional encoding and after self attention in both the Encoder and the Decoder.
It is to normalize each layer values to have \(mean=0\) and \(variance=1\). It can make gradient more stable and converge faster.
A little bit different to batch normalization, here it does the normalization at each unit of layer, and there is no need to wait for enough batch to do normalization.
Advantages of the Transformer Model
-
Parallelization: Transformers utilize a self-attention mechanism that allows for parallel processing of input sequences. This parallelization significantly speeds up training and inference compared to sequential models like recurrent neural networks (RNNs).
-
Scalability: Transformers can scale to handle both short and very long sequences, making them suitable for a wide range of applications, from short text to entire documents or even images.
-
Bidirectional Context: Unlike traditional RNNs, which process sequences sequentially, Transformers are inherently bidirectional. They consider both preceding and succeeding words when encoding a word, resulting in better contextual understanding.
-
Attention Mechanism: The self-attention mechanism allows Transformers to assign different weights to different parts of the input sequence, capturing long-range dependencies and contextual relationships effectively.
-
Transfer Learning: Transformers can be pretrained on large corpora and then fine-tuned for specific tasks, reducing the need for task-specific data and architectural changes. This transfer learning approach has become a standard practice in NLP and other domains.
-
Multimodal Applications: Transformers are not limited to text data and can be extended to handle multimodal inputs, such as combining text and images for tasks like image captioning or visual question answering.
-
Universal Applicability: Transformers are highly versatile and have been used for a wide range of NLP tasks, including text classification, machine translation, sentiment analysis, named entity recognition, and more. They are also applied in computer vision and speech processing.
-
Interpretable Attention: The attention weights in Transformers can be used to visualize and interpret which parts of the input sequence are most relevant for a given output, providing transparency and insight into the model’s decision-making process.
-
Language Independence: Transformers are adaptable to multiple languages and can be pretrained and fine-tuned for various language-specific tasks, facilitating cross-lingual applications.
-
Incorporation of Prior Knowledge: Transformers can be fine-tuned with domain-specific data or prior knowledge, making them suitable for specialized applications like scientific research, legal analysis, or medical diagnostics.
-
Architectural Flexibility: The Transformer architecture serves as a foundation for a wide range of models and extensions, such as BERT, GPT, and more. Researchers have developed numerous specialized Transformer-based models for various tasks and domains.
-
Open-Source Implementations: There are open-source libraries and pretrained models available for Transformers, making it accessible to the research and developer communities. This has led to widespread adoption and rapid progress in NLP and machine learning.
-
Continuous Advancements: The field of Transformers continues to evolve with ongoing research and developments, leading to improvements in model architectures, training techniques, and efficiency.
Disadvantages of the Transformer Model
-
Computational Intensity: Transformers are computationally intensive, especially for large models. Training and using them can require significant computational resources, including powerful GPUs or TPUs. This limits their accessibility to those without access to such resources.
-
Large Memory Requirements: Transformers need a lot of memory for both training and inference. This can be a limitation on hardware with limited memory capacity.
-
Training Data: Transformers require large amounts of training data to perform well. For some specialized tasks, obtaining sufficient training data can be a challenge.
-
Fine-tuning: While pretrained Transformers can be fine-tuned for specific tasks, fine-tuning still requires a fair amount of labeled data and can be sensitive to hyperparameters.
-
Lack of Common Sense and World Knowledge: Transformers don’t have an innate understanding of the world or common sense knowledge. They rely solely on patterns learned from their training data and might produce answers that are plausible-sounding but incorrect or nonsensical.
-
Interpretability: Transformers are often considered “black boxes.” It can be challenging to understand how they arrive at their decisions, which is a significant concern in applications where interpretability is crucial, like in legal or medical domains.
-
Biases in Training Data: Transformers can inherit biases present in their training data, potentially leading to biased or discriminatory outputs. Efforts are ongoing to mitigate this issue, but it remains a concern.
-
Sequential Processing: Despite their name, Transformers are not inherently designed for sequential data. While they can handle sequences, they don’t naturally model the temporal aspect as well as recurrent neural networks (RNNs).
-
Long-Range Dependencies: Although Transformers are known for their ability to handle long-range dependencies in sequences, they can still struggle with extremely long sequences due to their self-attention mechanisms. Specialized architectures like the “Longformer” have been proposed to address this issue.
-
Lack of Causality: Transformers are often bidirectional, which means they consider information from both past and future tokens. This makes them less suitable for tasks that require causal reasoning or predictions based only on past information. Some modifications, like the GPT-2 architecture, use causal (autoregressive) attention to address this.
-
Environmental Sensitivity: Transformers can be sensitive to input phrasing or wording. Slight changes in input phrasing can lead to different outputs, making them less robust in certain scenarios.
-
Storage and Deployment: Deploying large Transformer models in real-world applications can be challenging due to their size. It can strain storage and bandwidth resources, especially in scenarios where low-latency responses are required.
Language-Dependent Pretraining: Pretrained Transformers are often language-dependent, meaning that a model pretrained on one language may not perform as well on others. Multilingual models are emerging to address this issue.
Common Q & A:
Q: Why do we use sin and cos in the positional encoding?
A: The use of sine and cosine functions allows the positional encoding to have a smooth and continuous representation of position. The frequency of the sine and cosine functions varies across dimensions, ensuring that different positions have distinct representations. This helps the model to learn and generalize well based on the position of tokens in the input sequence.
The choice of sine and cosine functions is not unique; other functions could be used to achieve similar goals. The key is to provide the model with a way to differentiate between different positions in the input sequence. The sine and cosine functions were chosen in the original Transformer model for their smoothness and ability to capture positional information effectively.
Q: what do we need multi-head attention, not only one?
A: Multi-head attention uses multiple attention heads to capture diverse patterns and relationships in input sequences simultaneously. Each attention head learns different aspects of the data, promoting increased expressiveness and improving the model’s ability to generalize to various input patterns. By allowing parallelization during training, multi-head attention enhances computational efficiency. The combination of outputs from different attention heads provides the model with a richer understanding of the input sequence, reducing overfitting and aiding in the learning of diverse representations. This mechanism has proven effective in natural language processing tasks and sequence-to-sequence applications, contributing to the success of the Transformer model in capturing complex dependencies in sequential data.
Q: what do Q, K, V represent in the context of input sentence?
A: in the context of the Transformer model, each token within each input sentence has its own set of associated Query (Q), Key (K), and Value (V) vectors. The self-attention mechanism in the Transformer operates at the token level, and it enables the model to consider the relationships and dependencies between all tokens in a given input sentence.
Here’s a summary of the process:
(1) Embedding:
Each token in the input sentence is first embedded into a high-dimensional vector.
(2) Linear Projections:
Linear transformations are applied to the embedded vector of each token, resulting in separate Query (Q), Key (K), and Value (V) vectors for each token. These linear projections are parameterized by learned weight matrices.
(3) Self-Attention Mechanism:
The self-attention mechanism computes attention scores between the Query vectors and the Key vectors for all tokens in the sentence. These attention scores determine the importance of each token with respect to the others.
(4) Weighted Sum:
The attention scores are used to weight the corresponding Value vectors, and the weighted values are summed to obtain the output representation for each token in the sentence. This process is performed independently for each token within each input sentence. The use of individual Q, K, and V vectors for each token allows the model to capture complex relationships and dependencies within the input sentence. It provides the flexibility for the model to attend to different parts of the sentence for each position in the output sequence, contributing to the effectiveness of the Transformer architecture in natural language processing and sequence-to-sequence tasks.
Q: For inference, do we have output token input for the decoder part? how to make an inference for the output?
A: During inference in a Transformer model, where you are generating output sequences autoregressively (i.e., one token at a time), the decoding process typically involves the following steps:
(1) Start Token:
Initialize the decoding process with a special “start” token. This token is often denoted as
(2) Auto-regressive Generation:
Generate tokens one at a time in an auto-regressive manner. At each step, predict the next token based on the preceding tokens in the sequence.
(3) Greedy Decoding or Sampling:
Choose a decoding strategy, which could be greedy decoding or sampling. In greedy decoding, the token with the highest probability is selected at each step. In sampling, the next token is sampled from the predicted probability distribution, introducing a level of randomness.
(4) Update State:
Update the decoder state with the newly generated token, and use it as context for predicting the next token. Repeat:
Repeat steps (3) and (4) until a specified stopping criterion is met (e.g., generating an end-of-sequence token
It’s important to note that during inference, the self-attention mechanism in the decoder allows the model to attend to all previously generated tokens, capturing the context needed for generating the next token.
In practice, beam search is often used to explore multiple possible sequences simultaneously and improve the overall quality of generated sequences. Beam search maintains a set of the most likely partial sequences, expanding and selecting the top candidates at each step.
Q: How is the encoder different from the decoder?
A: There are some key differences in how they are applied in the encoder and decoder:
Encoder:
(1) Single Directional: In the encoder, self-attention is applied independently to each token in the input sequence. The attention mechanism allows each token to attend to all other tokens in the same input sequence, capturing dependencies within the sequence.
(2) No Future Information:
The encoder processes the input sequence in a forward direction. At any given step, each token only has information from tokens that precede it in the sequence, not from tokens that come after. This is because the model is designed to process the sequence in a causal (left-to-right) manner during training.
Decoder:
(1) Autoregressive Generation:
In the decoder, the self-attention mechanism is applied during the autoregressive generation of the output sequence. This means that at each step, the model generates the next token in the sequence and takes it into account when attending to previous tokens.
(2) Bidirectional Context:
Unlike the encoder, the decoder has bidirectional context. At any given decoding step, each token has information from both the preceding tokens in the target sequence (left context) and the tokens generated so far in the current decoding session (right context). Masked Self-Attention:
To ensure a causal generation process during training, the self-attention mechanism in the decoder is often masked to prevent attending to future tokens. This masking ensures that the model attends only to tokens generated up to the current decoding step. In summary, while the basic self-attention mechanism is similar, the differences in directionality, context, and masking make the application of self-attention in the encoder and decoder distinct. The encoder focuses on capturing relationships within the input sequence, while the decoder utilizes self-attention for autoregressive generation with bidirectional context.
Q: Why do we need scaling of the dot product attention before applying softmax?
A: Scaling the dot product in the self-attention mechanism of the Transformer is essential for training stability and balanced consideration of dimensions. The dot product operation can lead to exploding gradients during backpropagation, particularly in high-dimensional embedding spaces. To address this, a scaling factor, often the square root of the dimensionality ($\sqrt(d_k)$), is applied before the softmax function. This scaling prevents large gradients, stabilizing the training process.
Furthermore, the scaling operation ensures a balanced contribution from different dimensions. Without it, certain dimensions could dominate attention scores, causing an imbalance in the model’s focus on various aspects of the input. Dividing the dot products by $\sqrt(d_k)$ normalizes the contributions, promoting a more equitable consideration of all dimensions during attention calculation.
Q: Why do we use Q, K, V in transformer, can we just use any one, or two of them?
A: The use of Q (Query), K (Key), and V (Value) in the Transformer’s self-attention mechanism is a deliberate design choice that enhances the model’s ability to capture intricate relationships within sequences. The Query vectors determine where the model should focus in the input sequence, allowing for position-specific attention. Keys provide the context against which Queries are compared, influencing the attention scores. Value vectors store the actual information associated with each position in the sequence.
The inclusion of all three components enables the self-attention mechanism to comprehensively capture dependencies in the data. By examining the content of Query, context from Key, and information stored in Value, the model gains a nuanced understanding of the input sequence. Using only one or two components might limit the model’s capacity to grasp the full spectrum of dependencies and context in the data. This unique combination of Q, K, and V vectors in the Transformer contributes to its success in diverse tasks, allowing it to efficiently process sequential data and excel in natural language processing applications.
Reference:
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
Transformer code with Kera: https://www.tensorflow.org/text/tutorials/transformer#create_the_transformer
https://blog.research.google/2017/08/transformer-novel-neural-network.html