
Embeddings and Their Methods
-
date_range 02/10/2023 01:30 info
Embeddings are the backbone of modern machine learning, serving as powerful tools that transform raw data into meaningful representations in lower-dimensional spaces. They play a pivotal role in machine learning, providing a multitude of benefits ranging from dimension reduction, feature learning, and semantic representation to generalization, transfer learning, and computational efficiency. Recently I have joined a ML study group and I gave a presentation about the introduction to embeddings and their methods. Here is the summarization.
1. What is an embedding and what is it for?
It refers to a learned representation of data in a lower-dimensional space. They are vector representations of objects or data points that capture meaningful relationships and properties.
2. Why embeddings are essential in machine learning?
Dimension Reduction: Embeddings often have lower dimensions than the original data. Reducing the dimensionality of data can lead to more efficient computation and storage while preserving relevant information. This is especially valuable in high-dimensional spaces.
Feature Learning: Embeddings can learn informative features from raw data. Instead of handcrafting features, embeddings can be trained to automatically capture relevant patterns and relationships within the data. This is particularly useful in deep learning and neural networks.
Semantic Representation: In the case of word embeddings, such as Word2Vec or GloVe, words with similar meanings are represented as vectors close to each other in the embedding space. This semantic similarity can improve the performance of natural language processing (NLP) tasks, as models can leverage the learned word relationships.
Generalization: Embeddings can help models generalize better to unseen data. By learning meaningful representations, models can recognize similarities and differences between data points, allowing them to make informed predictions or classifications even on examples not encountered during training.
Transfer Learning: Pre-trained embeddings can be transferred to new tasks, reducing the need for extensive training on large datasets. For example, pre-trained word embeddings can be fine-tuned for specific NLP tasks, saving both time and computational resources.
Visualization: Embeddings provide a way to visualize complex data in a lower-dimensional space, making it easier for humans to understand and interpret patterns and relationships.
Computational Efficiency: Embeddings can significantly speed up computation. For example, when dealing with text data, embedding words into dense vectors allows for efficient vectorized operations compared to sparse one-hot encodings.
Handling Missing Data: Embeddings can handle missing data gracefully. If a feature (e.g., a word in text data) is missing, you can still use the embedding for the known features, allowing models to make reasonable predictions.
Interpolation and Extrapolation: Embeddings can capture the relationships between data points in a continuous manner. This enables interpolation (predicting values between existing data points) and extrapolation (predicting values beyond the observed range) for certain tasks.
3. Embedding Areas:
In NLP, it’s commonly to see the word embeddings. They represent words as vectors in a continuous, lower-dimensional space. Each word is mapped to a point in this space, where the position of the point captures semantic relationships between words. Word embeddings allow machine learning models to capture the meaning and context of words, which is crucial for tasks like sentiment analysis, language translation, and text generation.
In the computer vision area, image embeddings are used to represent images as vectors in a lower-dimensional space. These embeddings capture features and characteristics of images, enabling machine learning models to understand and work with visual data. Image embeddings can be learned through deep learning architectures such as convolutional neural networks (CNNs).
Other Text embedding (e.g. use for user profile and product descriptions), there are involved category embedding.
Category embedding, often referred to as categorical embedding or entity embedding, is a technique used to represent categorical variables as continuous-valued vectors in a lower-dimensional space. Categorical variables are variables that represent different categories or classes, such as gender, country, product IDs, or any other non-numeric attributes.
4. Methods:
4.1 Word Embedding Methods:
- Word2Vec:
Developed by Google, Word2Vec is a set of techniques to create word embeddings based on predicting words in a context window. Includes CBOW (Continuous Bag of Words) and Skip-gram architectures. Known for capturing semantic relationships between words and their context.
Here is the architecture of CBOW.

– Example of CBOW
A simple example of how Continuous Bag of Words (CBOW) works with a sentence:
(1) Sentence: “The quick brown fox jumps over the lazy dog.”
(2) Data Preparation:
Tokenize the sentence: [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, “.”] Create a vocabulary: [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, “.”] Context and Target:
Let’s consider a context window of size 2. For each target word, select the two words before and after it as context words. Training Data:
For “quick”, context: [“The”, “brown”] For “brown”, context: [“quick”, “fox”] For “fox”, context: [“brown”, “jumps”]
(3) Model Architecture:
Build a CBOW model that takes the context word indices as input. Use an embedding layer to convert the context words to vectors. Average the vectors to get the context representation. Pass the averaged vector through a hidden layer or directly to the output layer.
(4) Training:
Train the CBOW model using the context and target word pairs. The model learns to predict the target word based on its context. Word Embeddings:
Once trained, the embedding vectors for each word represent their semantic meanings. Words with similar meanings will have similar vectors. For example, “quick” and “fast” might have similar vectors due to their similar contexts. Inference:
(5) Inference:
Now, you can use the trained word embeddings for various tasks. For instance, you can calculate the similarity between word vectors, or use them as input features for other machine learning models. This example demonstrates how CBOW captures the relationships between words in a sentence by considering their local contexts. Keep in mind that actual implementations involve more complex architectures, larger vocabularies, and training on extensive text corpora for meaningful word embeddings.
– Example of skip-gram:
Here’s a simple example of how the Skip-Gram model works using a sentence:
Here is the architecture of skip-gram.

(1) Sentence: “The quick brown fox jumps over the lazy dog.”
(2) Data Preparation:
Tokenize the sentence: [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, “.”] Create a vocabulary: [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, “.”]
Context and Target:
Consider a target word and predict its context words. Let’s use a context window of size 2: two words before and after the target.
Training Data:
For “quick”, predict: [“The”, “brown”] For “brown”, predict: [“quick”, “fox”] For “fox”, predict: [“brown”, “jumps”]
(3) Model Architecture:
Build a Skip-Gram model that takes the target word index as input. Use an embedding layer to convert the target word to a vector. Predict the context words based on the target word’s embedding.
(4) Training:
Train the Skip-Gram model to predict context words for each target word. The model learns to generate context words that are likely to appear around the target word. Word Embeddings:
After training, the embedding vectors for each word represent their semantic meanings. Words with similar meanings will have similar vectors. For example, “quick” and “fast” might have similar vectors due to their similar contexts. Inference:
(5) Infernece:
Similar to CBOW, you can use the trained word embeddings for various tasks. Calculate the similarity between word vectors or use them as input features for machine learning models. Skip-Gram focuses on predicting context words from a given target word, in contrast to CBOW that predicts a target word from its context. The process allows capturing the relationships between words by considering their co-occurrences in a sentence.
- GloVe (Global Vectors for Word Representation):
GloVe creates word embeddings by factorizing the word co-occurrence matrix. Focuses on capturing global word co-occurrence statistics and semantic meanings.
- fastText:
An extension of Word2Vec that takes into account subword information using character n-grams. Useful for handling out-of-vocabulary words and capturing morphological information.
- ELMo (Embeddings from Language Models):
ELMo creates embeddings by training a bidirectional LSTM language model on large text datasets. Provides multiple layers of embeddings to capture context at various levels.
- ULMFiT (Universal Language Model Fine-tuning):
ULMFiT is a transfer learning approach that pre-trains a language model on a large corpus and fine-tunes it for specific tasks. Captures general language knowledge and can be fine-tuned for specific tasks.
- BERT (Bidirectional Encoder Representations from Transformers):
A transformer-based model pre-trained on large text corpora using masked language modeling and next sentence prediction. Generates contextualized embeddings by considering both left and right context.
- Transformer-XL:
An extension of the transformer architecture, Transformer-XL captures longer-range dependencies by considering segments of text beyond the fixed context window. Beneficial for tasks requiring understanding of long-range contexts.
- USE (Universal Sentence Encoder):
USE generates embeddings for sentences or short texts using a transformer-based model trained on various tasks. Captures sentence-level semantics.
- Doc2Vec:
An extension of Word2Vec that generates document embeddings. Learns to represent documents as vectors while considering word order.
- Flair:
Flair combines forward and backward LSTM language models to generate contextualized word embeddings. Known for its contextual string embeddings and sentiment analysis capabilities.
4.2 Image Embedding Methods:
- Convolutional Neural Networks (CNNs):
CNNs are the most widely used method for creating embeddings in computer vision. They automatically learn hierarchical features from images through convolutional layers. Pre-trained CNNs are often used as feature extractors for various tasks.
- Siamese Networks:
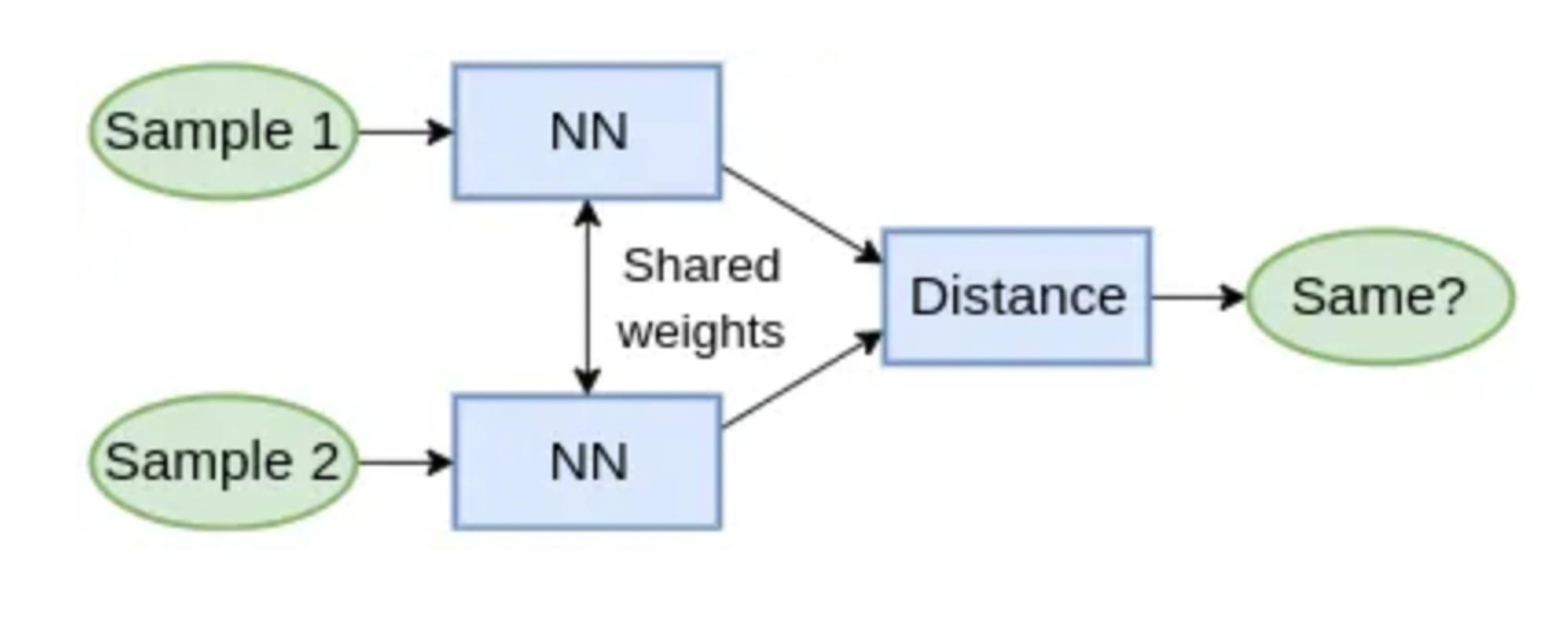
Siamese networks are popular for learning similarity or dissimilarity between images. They generate embeddings that encode relationships between images for tasks like image similarity and face verification.
Here is the architecture of Siamese Networks:
- Triplet Networks:
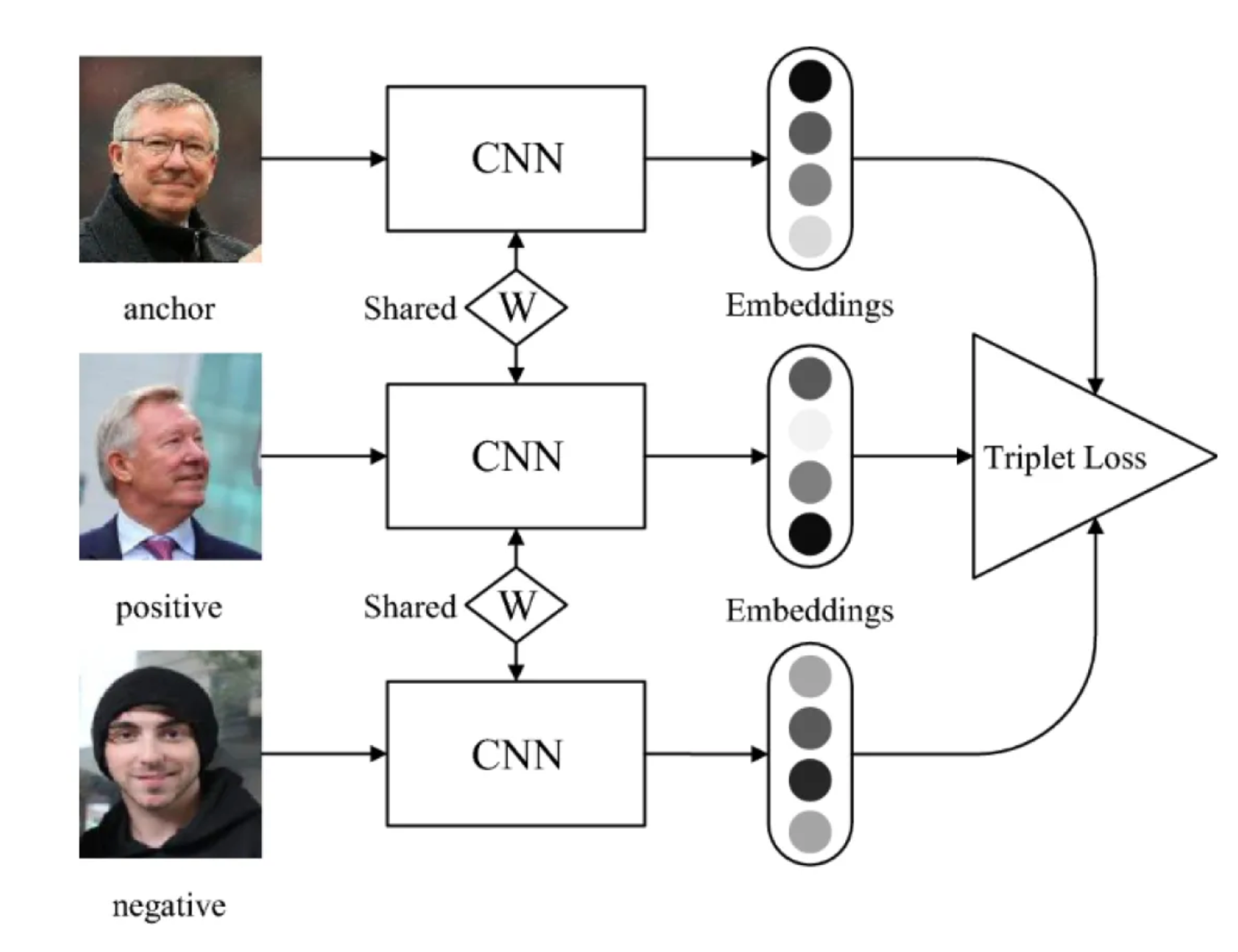
Triplet networks learn embeddings that ensure similar images are closer in the embedding space than dissimilar images. Effective for image retrieval and clustering tasks.
Here is the architecture of Triplet Networks:
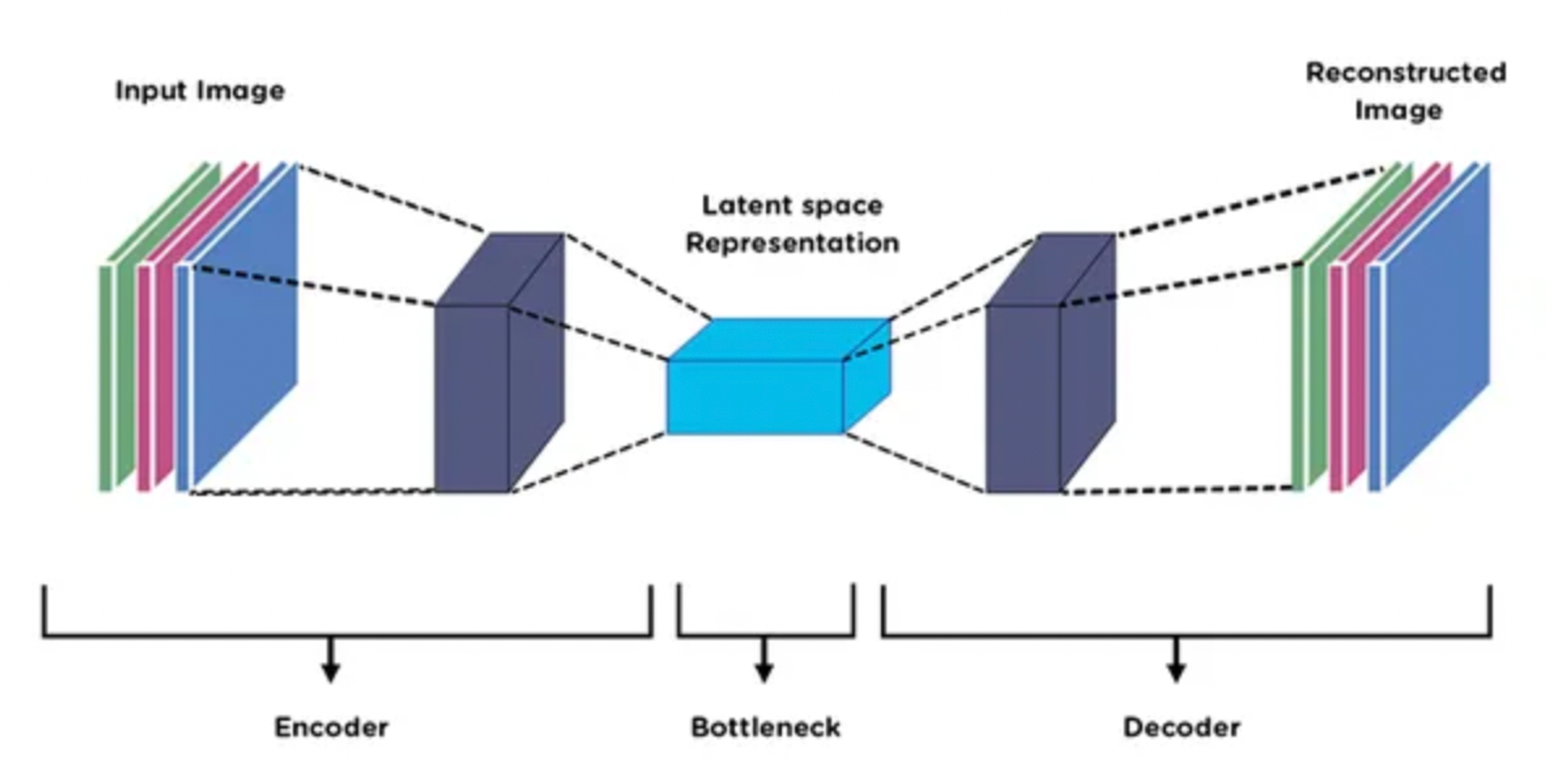
- Autoencoders:
Autoencoders learn to reconstruct input images and generate embeddings in the bottleneck layer. Variational Autoencoders (VAEs) introduce probabilistic modeling to generate embeddings.
Here is the architecture of Triplet Networks:
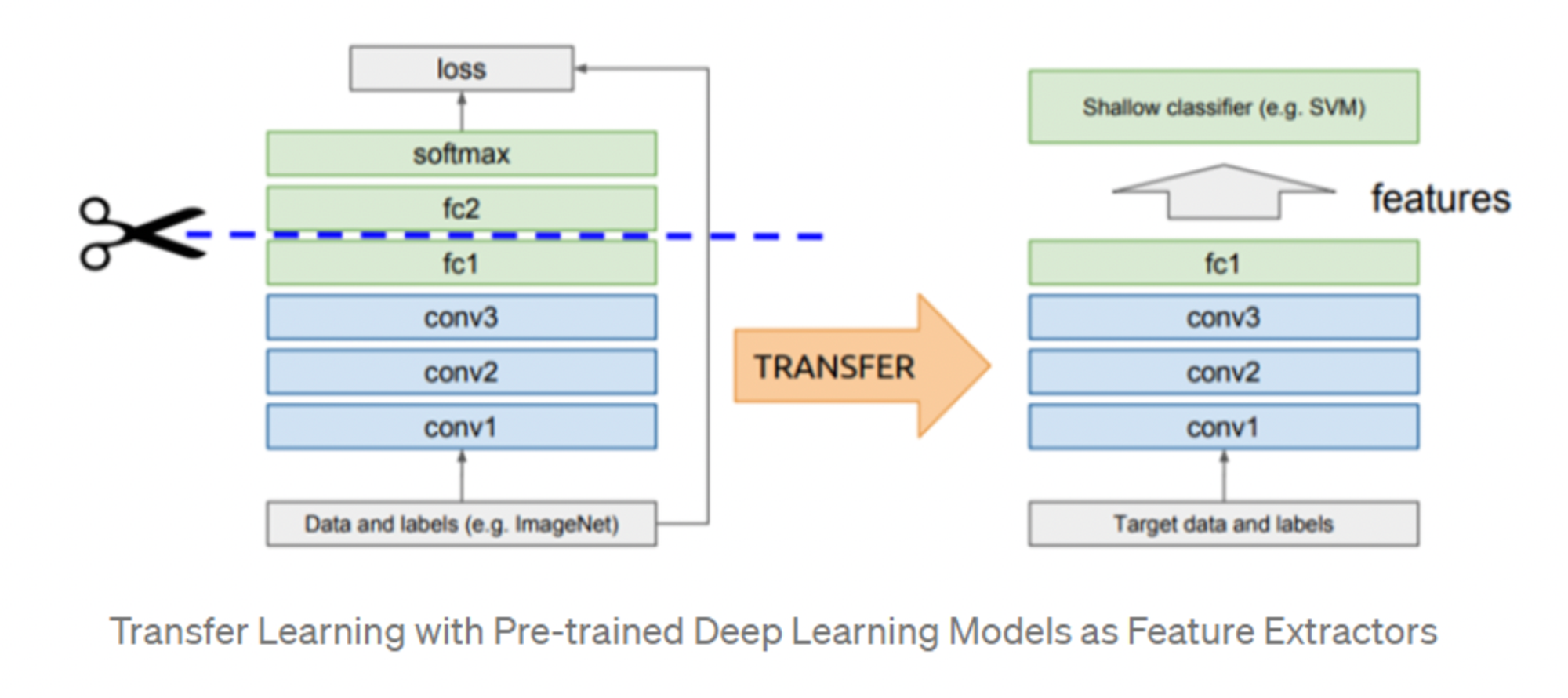
- Pre-trained Models for Transfer Learning:
Pre-trained models like VGG, ResNet, and Inception are used as feature extractors. They capture high-level features from images and are fine-tuned for specific tasks.
Here is the architecture of Pre-trained Networks:
- Global and Local Descriptors:
Global descriptors capture overall image characteristics, while local descriptors (e.g., SIFT, ORB) capture keypoints and features in regions. Used for object detection, image recognition, and more.
- Bag-of-Visual-Words (BoVW):
BoVW divides images into regions, quantizes local descriptors, and generates histograms of visual words. Used for image classification, image retrieval, and object recognition.
Here is the diagram of BoVW:
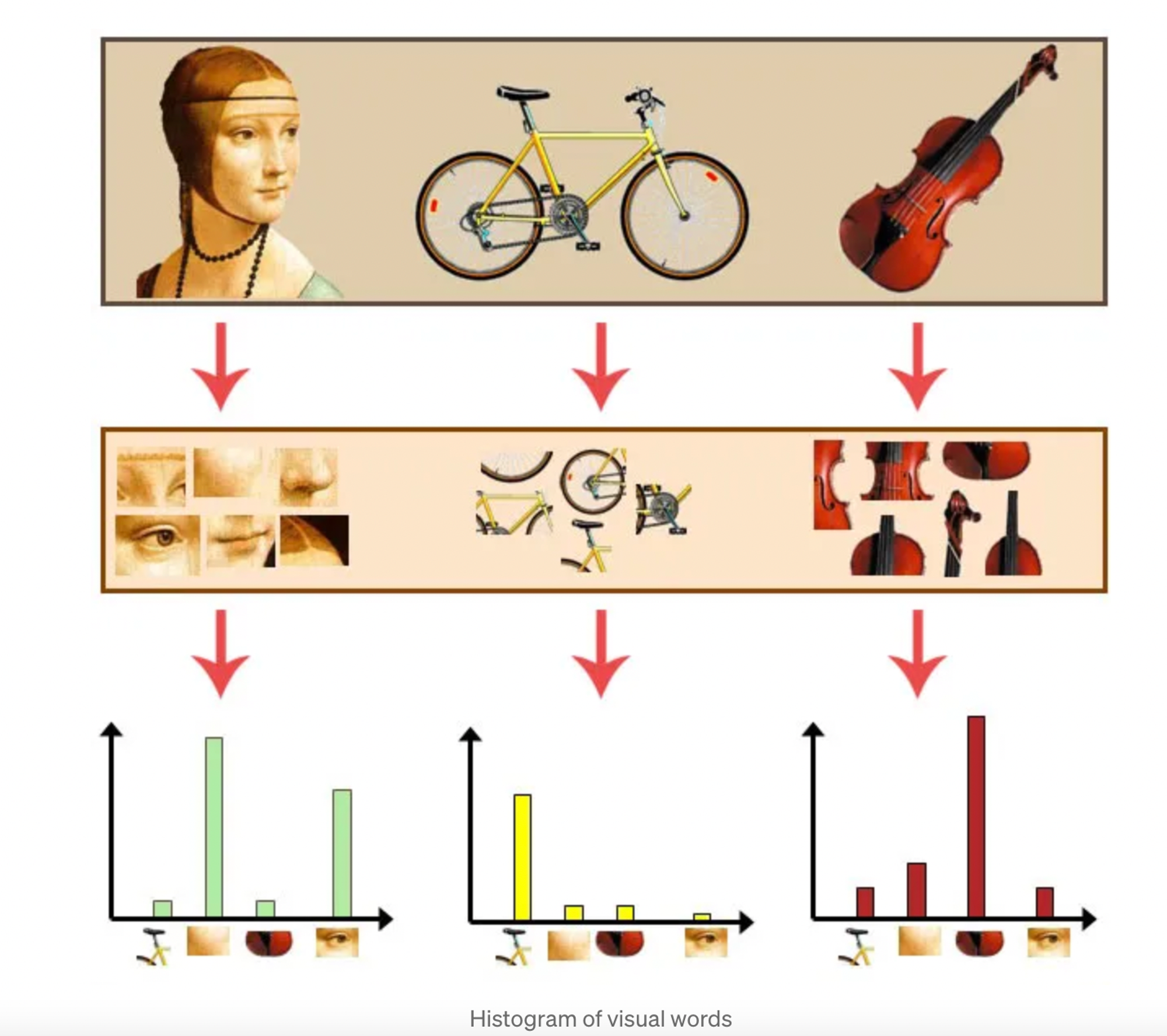
- Deep Metric Learning:
Deep metric learning methods learn embeddings such that similar images are closer while dissimilar images are farther apart. Used for image similarity, face recognition, and person re-identification.
- Graph-Based Methods:
Represent images as nodes in a graph and generate embeddings using graph structure. Used for tasks like image classification and clustering.
- Attention Mechanisms:
Attention mechanisms, popularized by transformers, can be applied to images to generate context-aware embeddings. Used for tasks like image captioning and image generation.
4.3 Category embedding:
- Label Encoding:
Assigns a unique integer to each category in the variable. Useful for categorical variables with an ordinal relationship, where the order matters.
- One-Hot Encoding:
Creates binary columns for each category, where each column indicates the presence or absence of a category. Suitable for nominal categorical variables with no intrinsic order.
- Binary Encoding:
Combines aspects of one-hot encoding and label encoding to represent categories using binary digits. Reduces the dimensionality compared to one-hot encoding while maintaining meaningful representations.
- Frequency Encoding:
Replaces categories with their frequency of occurrence in the dataset. Can be useful when the frequency of a category relates to its importance.
- Target Encoding (Mean Encoding):
Replaces categories with the mean of the target variable for each category. Often used in predictive modeling tasks where the target variable is involved.
- Embedding Layers (Neural Networks):
Creates dense representations of categorical variables within neural network architectures. Each category is represented by a continuous vector, learned through model training.
- Entity Embeddings of Categorical Variables (Entity Embedding Layer):
Similar to neural network embeddings but used specifically for categorical variables. Used in recommendation systems and other tasks where relationships between categories matter.
- Hashing Trick:
Maps categories to a fixed number of bins using hash functions. Useful for high-cardinality categorical variables.
- Feature Crossing and Polynomial Features:
Combines multiple categorical variables or their interactions to create new features. Can capture relationships that are not evident in individual categories.
- Domain-Specific Encodings:
Utilizes domain knowledge to create meaningful numerical representations. Examples include business-specific encodings based on industry expertise.
Reference:
- http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
- https://analyticsindiamag.com/word2vec-vs-glove-a-comparative-guide-to-word-embedding-techniques/
- https://medium.com/@mariamestre/fasttext-stepping-through-the-code-259996d6ebc4
- https://www.mihaileric.com/posts/deep-contextualized-word-representations-elmo/
- https://paperswithcode.com/method/ulmfit
- https://arxiv.org/abs/1810.04805
- https://arxiv.org/abs/1901.02860
- https://arxiv.org/abs/1803.11175
- https://medium.com/wisio/a-gentle-introduction-to-doc2vec-db3e8c0cce5e
- https://medium.com/@rinkinag24/a-comprehensive-guide-to-siamese-neural-networks-3358658c0513
- https://www.v7labs.com/blog/triplet-loss
- https://analyticsindiamag.com/a-comparison-of-4-popular-transfer-learning-models/
- https://www.baeldung.com/cs/image-processing-feature-descriptors
- https://towardsdatascience.com/bag-of-visual-words-in-a-nutshell-9ceea97ce0fb
- https://d2l.ai/chapter_attention-mechanisms-and-transformers/index.html
- https://towardsdatascience.com/entity-embeddings-for-ml-2387eb68e49
- https://medium.com/flutter-community/dealing-with-categorical-features-with-high-cardinality-feature-hashing-7c406ff867cb
- https://medium.com/@rakeshsharma.pr/why-feature-crosses-are-still-important-in-machine-learning-4ee49189a2ca