
Analysis of Practical Lessons from Predicting Clicks on Ads at Facebook
-
date_range 06/11/2022 00:30 infosortdefaultlabelMachine learningData ScienceAdsCTR
Here we introduce a paper from Facebook about ads click through rate prediction. It was an old paper published in 2014, but I believe it still has lots of good practices which we could learn from for ads service.
Q: What is the problem?
It is to predict the click through rate (CTR) for each ad impression.
Q: How is it mathematically modeled?
The groud truth label is \({-1, 1}\) indicating a click or no-click. It could be modeled as a binary classification problem, and we can get the probability of an ad clck.
Q: What metrics is used?
Normalized Cross-Entropy (NE) and calibration as our major evaluation metric. NE is the equivalent to the average log loss per impression divided by what the average log loss per impression would be if a model predicted the background click through rate (CTR) for every impression. The background CTR is the average empirical CTR of the training data set.
Calibration is the ratio of the average estimated CTR and empirical CTR, that is, the ratio of the number of expected clicks to the number of actually observed clicks.
Q: What ML modeled is used?
It uses a hybrid model structure, the concatenation of boosted decision trees and of a probabilistic sparse linear classifier (logistic regression). Input features are transformed by means of boosted decision trees. The output of each individual tree is treated as a categorical input feature to a sparse linear classi er. Boosted decision trees prove to be very powerful feature transforms.
The a cascaded model is shown below:
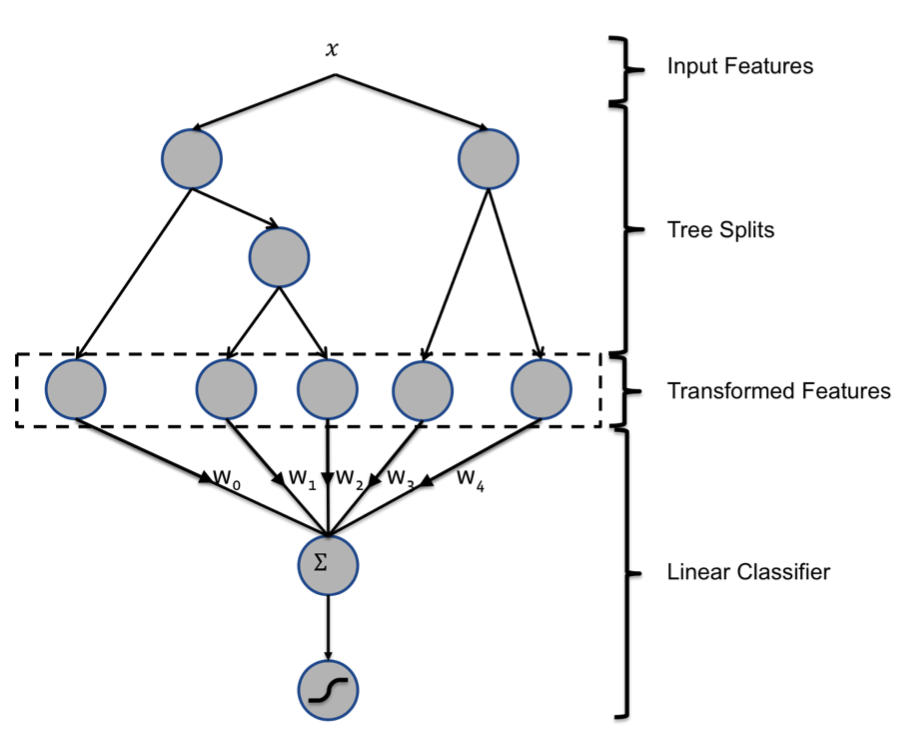
Q: How is the Data selected for training and testing here?
Offine training data uses an arbitrary week of the 4th quarter of 2013, which is similar to that observed online. They partition the stored offine data into training and testing and use them to simulate the streaming data for online training and prediction.
Q: What features are used?:
Features used in the Boosting model can be categorized into two types: contextual features and historical features.
The value of contextual features depends exclusively on current information regarding the context in which an ad is to be shown, such as the device used by the users or the current page that the user is on. On the contrary, the historical features depend on previous interaction for the ad or user, for example the click through rate of the ad in last week, or the average click through rate of the user.
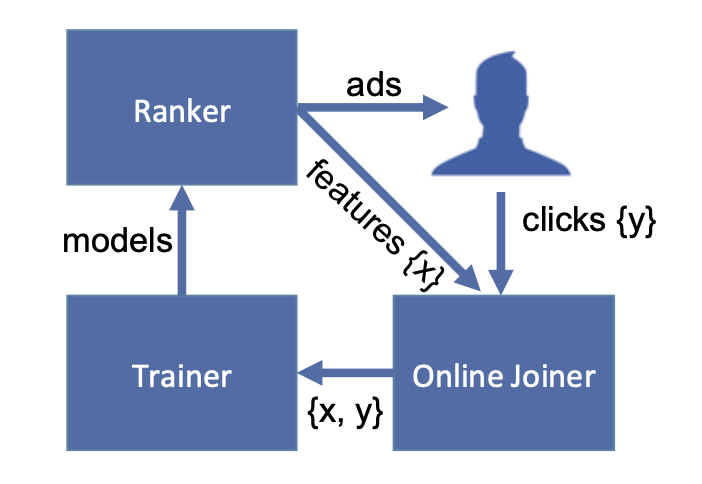
Q: What the frequency of training?
It uses online learning. It trains the linear classifier online only as the labelled ad impressions arrive. This Figure below shows the data flow for online learning. Real-time training data is generated through user clicking ads or not from ranker. If the user clicks an add, it will add to be a positive example, otherwise it will be a negative example after a window time (tuned parameter).
Q: How to deal with the big training data?
A common technique used to control the cost of training is reducing the volume of training data. Here it uses techniques for down sampling data–uniform subsampling and negative down sampling.
Q: What are the takeway of the paper?
-
A hybrid model which combines decision trees with logistic regression outperforms either of these methods on their own by over 3%.
-
A number of fundamental parameters impact the final prediction performance of our system.
-
The most important thing is to have the right features: those capturing historical information about the user or ad dominate other types of features.
-
Picking the optimal handling for data freshness, learning rate schema and data sampling improve the model slightly, though much less than adding a high-value feature, or picking the right model to begin with.
-
Data freshness matters. It is worth retraining at least daily. Fresher training data leads to more accurate predictions. This motivates the idea to use an online learning method to train the linear classifier.
-
Decision trees are very powerful input feature transformations, that significantly increase the accuracy of probabilistic linear classifiers.
Q: What else could be learned?
-
The experimental results shows that historical features provide considerably more explanatory power than contextual features.
-
Transforming real-valued input features with boosted decision trees significantly increases the prediction accuracy of probabilistic linear classifiers.
-
Best online learning method: Linear regression with per-coordinate learning rate.
Reference:
He, X., Pan, J., Jin, O., Xu, T., Liu, B., Xu, T., Shi, Y., Atallah, A., Herbrich, R., Bowers, S. and Candela, J.Q., 2014, August. Practical lessons from predicting clicks on ads at facebook. In Proceedings of the eighth international workshop on data mining for online advertising (pp. 1-9).